UCSC Students Predictions of Ethics + Income

Written by Radhika Gathwala
Income prediction is a powerful tool for businesses in order to target potential customers and capitalize their profit margins. For example, a company may choose to prioritize its wealthier customers to more premium products. This is also common in real estate and loan agencies. This past quarter I explored different aspects of fairness with algorithmic decision making via Lise Getoor’s Ethics and Algorithms course at UC Santa Cruz.
For our course project, I worked with two of my classmates, Kartik Panchal and Rohan Krishnaswamy, to predict if an individual makes more than $50,000 annually using US adult census data from 1996. We acknowledged initial biases such as how our data was gathered, which may inaccurately reflect the US population as a whole, and the time frame. We ran two machine learning models on three different versions of the same dataset after preprocessing and feature engineering to better represent our data. A couple of our models predicted whether an individual made more than 50,000 with an accuracy of 85%, which is why we chose to analyze different metrics like precision, recall, and false negative rate (FNR) to determine our best performing machine learning model, logistic regression. We’ll define these three metrics below:
Precision is the percentage of people that make more than $50,000 over the number of people our model predicted would make more than $50,000.
Recall is the number of people making more than $50,000 that our model predicts correctly over all the people making more than $50,000.
False Negative Rate (FNR) is the percentage our model predicted the person makes less than or equal to $50,000 but in reality they make more than $50,000.
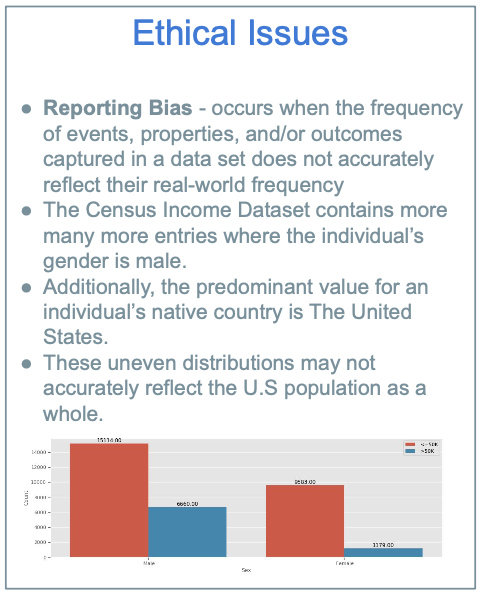
When comparing the FNR amongst our gender attributes we observed there was a FNR of 46.7% for males and a FNR of 60% for females, showing our model is more biased towards females. Other attributes we observed with the highest FNR were race, relationship/marital status, education, and occupation. We believe these results are due to either reporting or historical biases.
Many companies collect and leverage their user’s data to avoid facing negative consequences like loss. This results in issues, however, such as data privacy and bias against some individuals over others, becoming a question of what’s ethical and what’s not. A lot of time users don’t even know their data is being collected which makes it even worse, because businesses are collecting user data without even notifying users.
If we favor the business/companies, then our model with the highest precision would be the best. This would result in a lower error rate as well and minimize any potential clients that may not deliver. On the other hand, the recall metric would be ideal for customers as it would prevent any exclusion on any individuals (higher recall will increase the chance that they’re classified to make more than $50,000), but would result in lower precision.